3.3 Data for scaffold tasks
(1) Citation worthiness sampling
- 인용된 문장만 positive labels로 분류
(2)인용 mark 제거
(e.g., [1]) or name-year combinations (e.g, Lee et al (2012)) 와 같은 인용마크들을 제거
(3) Section title mapping
ACL-ARC데이터와 시멘틱스칼라 데이터 각각의 인용문과 정규화된 Section title을 매핑
normalized section titles: “introduction”, “related work”, “method”, “experiments”, “conclusion”
매핑되지 않은 문장들은 삭제
- scaffold tasks 결과
- ACL-ARC
Section title scaffold - 47K, Citation worthiness 50K
- SciCite
Section title scaffold - 91K, Citation worthiness 73K
4 Experiments
4.1 Implementation
- AllenNLP 라이브러리를 사용하여 구현 (Gardner et al., 2018).
- Word representations 위해 100차원 GloVe vectors (Pennington et al., 2014) 사용함.
- Contextual representation을 위해 Output size 1,024차원의 ELMo vector를 사용 (released by Peters et al. (2018))
- Single-layer BiLSTM 사용(hidden dimension size = 50)
- 각 Scaffold tasks는 20 hidden nodes와 activation function "ReLU" (Nair and Hinton, 2010), Dropout 0.2 (Srivastava et al., 2014)
- hyperparameter
- ACL-ARC
Citation worthiness saffold: λ2=0.08, λ3=0
Ssection title scaffold: λ3=0.09, λ2=0
Both scaffolds: λ2=0.1, λ3=0.05. Batch size: 8
- SciCite
0.0 to 0.3 grid search, Batch size: 32
실험에 사용된 Code 와 Data, Model은 SciCite Github 참고
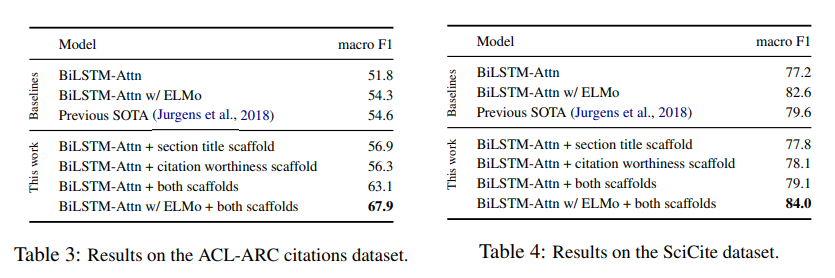
4.3 Results - SciCite와 ACL-ARC F1-score 비교
4.3 Results - SciCite와 ACL-ARC 의도분류 성능비교
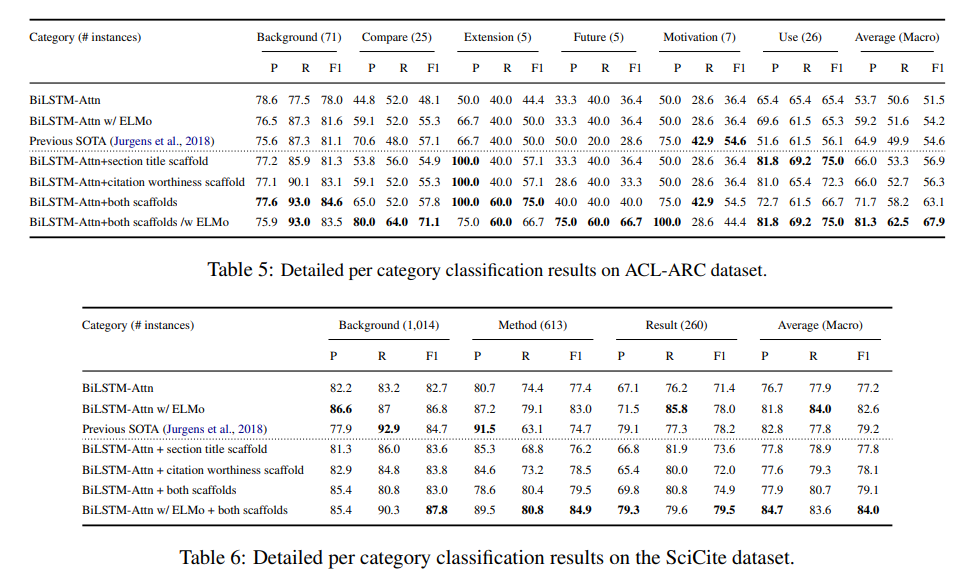
- 문장(instances)이 많은 카테고리의 경우 일반적으로 결과가 좋게 나타남(ex ACL의 Background vs Future Work)
- 학습대상문장이 적을경우 최적매개변수(optimal paramete)를 학습하기 어렵기 때문임.
4.4 Analysis
성능이 가장 뛰어난 두 모델, ‘BiLSTM-Attn w/ ELMo + both scaffolds’ 와 ‘BiLSTMAttn w/ ELMO’(baseline)의 attention weight 비교함.(Fig.3)

- (Fig. 3a)의 실제 레이블은 Future Work, 단어 "future" 주변에 더 많은 가중치를 부여함,
baseline 모델은 "compare"에 더 많은 가중치를 부여하여 Compare 레이블로 잘못 예측함.
- (Fig. 3b)에서 실제 레이블은 Result Comparison, 비교의 의미 "than"에 가중치 부여
baseline모델은 “analyzed seprately” 에 가중치를 부여하여 "Background"로 잘못분류함.
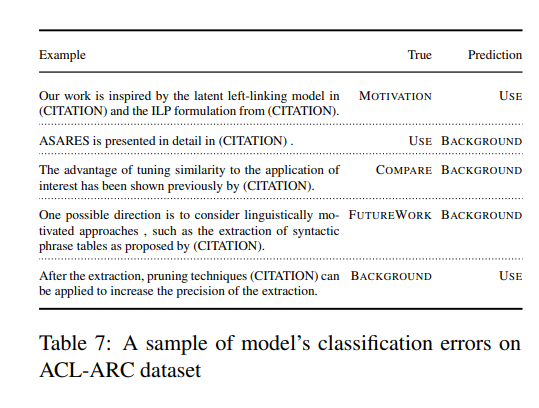
- Error analysis
- (Fig.4) classification error를 나타냄, 오류는 주로 Background 카테고리에서 발생.
- 표7의 첫 문장은 “model in (citation)” and “ILP formulation from (citation)” 부분때문에 노이즈가 발생하여 오분류됨.
(Motivation 분류의 학습데이터 수가 적기 때문일 수 있음)
- 네번째 문장은 분류가 애매함.
- 이러한 유형의 오류를 방지 할 수있는 방법은 학습을 위한 input 데이터를 추가 하거나
모델링 시에 extended surrounding context를 적용하는 것임
위 오류 개선을 위해 BiLSTM을 사용하여 extended surrounding context 인코딩을 실시하고 main citation context vector (z)와 연결했지만, 전체적으로 노이즈가 늘어나 성능이 크게 저하됨을 알 수 있음.
5 Related Work
기존에 인용의도 분류에 관한 연구들 (Stevens and Giuliano, 1965; Moravcsik and Murugesan, 1975; Garzone and Mercer, 2000; White, 2004; Ahmed et al., 2004; Teufel et al. , 2006; Agarwal et al., 2010; Dong and Schafer ¨, 2011).은 인용의도 분류의 범주가 너무 세분화 되어있고, 어떤 분류범주는 거의 없는경우도 많아 과학문헌의 자동분석에는 유용하지 않다.
이러한 문제를 해결하기 위해 Jurgens et al. (2018)은 인용의도에 대한 6가지 분류범주를 제안했다
본 논문에서는 (1)Jurgens가 제안한 분류범주와 (2)우리가 제안한 좀더 "범용적인" 분류범주 두가지를 비교했다.
그 결과, domainspecific한 기존의 Scheme들과 달리, 우리의 Scheme은 일반적인 과학적 담론에 적합함을 확인할 수 있었다.
자동인용의도분류 초기에는 규칙기반 위주의 연구가 이뤄짐(Garzone and Mercer, 2000; Pham and Hoffmann, 2003))
이후 다양한 연구들이 진행되었으며, 우리는 데이터 기반의 방법으로 인용의도를 분류할 수 있음을 확인했다.
이를 “scaffold”라는 용어를 차용하여 인용의도 분류를 위한 novel scaffold neural model 을 제안한다
6 Conclusions and future work
이 연구에서 우리는 과학적 담론과 관련된 구조적 속성이 인용 의도 분류를 알리는 데 효과적으로 사용될 수 있음을 보여줍니다.
우리가 제안한 모델은 기존 ACL-ARC 데이터 세트에서 최고점(F1-score 67.9)으로, 기존연구의 점수보다 13.3점 높았다.
새로운 대규모 데이터셋인 SciCite에서도 우리 모델의 성능은 더 우수하며, scientific domains에 범용적으로 활용할 수 있다.
본 논문의 최종제출시점에 Beltagy et al (2019)은 과학 텍스트 pre-trained model인 BERT contextualized representation model(Devlin et al., 2018)이 SciCite데이터셋에서 더 좋은 결과를 얻을 수 있음을 보여주었다